Step 2: Passing parameters to the pipeline¶
Overview¶
The python functions which do the actual work of each stage or task of a Ruffus pipeline are written by you.The role of Ruffus is to make sure these functions are called in the right order, with the right parameters, running in parallel using multiprocessing if desired.This step of the tutorial explains how these pipeline parameters are specified.By letting Ruffus manage your pipeline parameters, you will get the following features for free:
- only out-of-date parts of the pipeline will be re-run
- multiple jobs can be run in parallel (on different processors if possible)
- pipeline stages can be chained together automatically
Let us start with the simplest case where a pipeline stage consists of a single job with one input, one output, and an optional number of extra parameters:
@files¶
The @files decorator provides parameters to a task.
Note
All strings in the first two parameters are treatd as input and output files (respectively).
Let us provide input and outputs to our new pipeline:
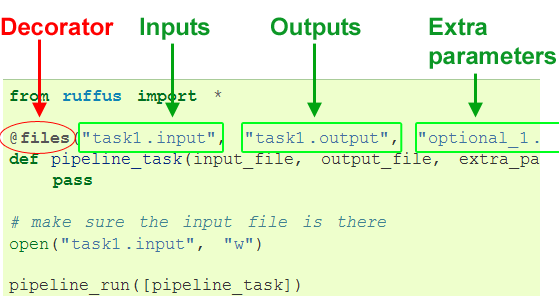
This is exactly equivalent to the following function call:
pipeline_task('task1.input', 'task1.output', 'optional_1.extra', 'optional_2.extra')and the output from Ruffus will thus be:

Specifying jobs in parallel¶
Each task function of the pipeline can also be a recipe or rule which can be applied at the same time to many different parameters.For example, one can have a compile task which will compile any source code, or a count_lines task which will count the number of lines in any file.In the example above, we have made a single output by supplying a single input parameter. You can use much the same syntax to apply the same recipe to multiple inputs at the same time.Note
Each time a separate set of parameters is forwarded to your task function, Ruffus calls this a job. Each task can thus have many jobs which can be run in parallel.
Instead of providing a single input, and a single output, we are going to specify the parameters for two jobs at once:
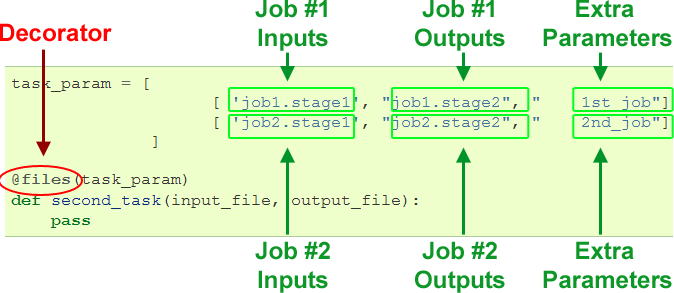
To run this example, copy and paste the code here into your python interpreter.
This is exactly equivalent to the following function calls:
second_task('job1.stage1', "job1.stage2", " 1st_job") second_task('job2.stage1', "job2.stage2", " 2nd_job")
- The result of running this should look familiar:
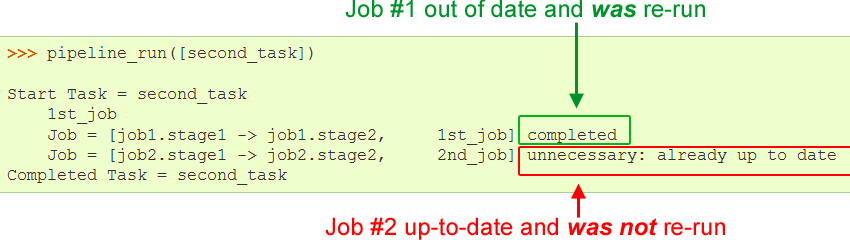
Start Task = second_task 1st_job Job = [job1.stage1 -> job1.stage2, 1st_job] completed 2nd_job Job = [job2.stage1 -> job2.stage2, 2nd_job] completed Completed Task = second_task
Multi-tasking¶
Though, the two jobs have been specified in parallel, Ruffus defaults to running each of them successively. With modern CPUs, it is often a lot faster to run parts of your pipeline in parallel, all at the same time.
To do this, all you have to do is to add a multiprocess parameter to pipeline_run:
>>> pipeline_run([pipeline_task], multiprocess = 5)In this case, ruffus will try to run up to 5 jobs at the same time. Since our second task only has two jobs, these will be started simultaneously.
Up-to-date jobs are not re-run¶
A job will be run only if the output file timestamps are out of date.If you ran the same code a second time,>>> pipeline_run([pipeline_task])nothing would happen becausejob1.stage2 is more recent than job1.stage1 andjob2.stage2 is more recent than job2.stage1.
- However, if you subsequently modified job1.stage1 and re-ran the pipeline:
- You would see the following:
Input and output data for each job¶
In the above examples, the input and output parameters are single file names. In a real computational pipeline, the task parameters could be all sorts of data, from lists of files, to numbers, sets or tuples. Ruffus imposes few constraints on what you would like to send to each stage of your pipeline.
Ruffus will, however, look inside each of your input and output parameters to see if they contain any names of up to date files.
If the input parameter contains a glob pattern, that will even be expanded to the matching file names.
For example,
the input parameter for our task function might be all files which match the glob *.input plus the number 2the output parameter could be a tuple nested inside a list : ["task1.output1", ("task1.output2", "task1.output3")]Running the following code:
from ruffus import * @files(["*.input", 2], ["task1.output1", ("task1.output2", "task1.output3")]) def pipeline_task(inputs, outputs): pass # make sure the input files are there open("task1a.input", "w") open("task1b.input", "w") pipeline_run([pipeline_task])will result in the following function call:
pipeline_task(["task1a.input", "task1b.input", 2], ["task1.output1", ("task1.output2", "task1.output3")])and will give the following results:
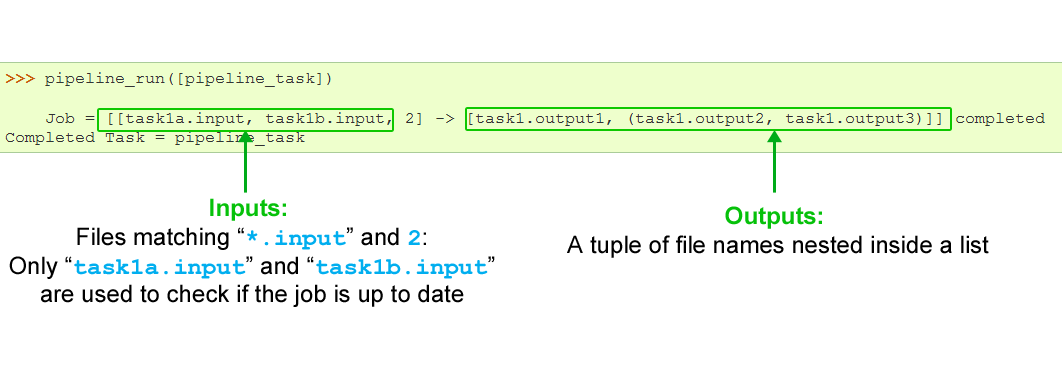
- The files
and
"task1.output1" "task1.output2" "task1.output3"will be used to check if the task is up to date. The number 2 is ignored for this purpose.